强化学习:⼈⼯智能的交互式学习范式
这是我在工信部上给工信部各系统的研究人员做的一个 1 小时分享。
开场(约 3 分钟)
各位朋友,大家好。(简单自我介绍)
接下来这一个小时,我们来聊一聊人工智能里面一个既基础又前沿的话题——强化学习。
大家最近一定经常听到“大模型”“大语言模型”“智能体(Agent)”这些词,但很多时候,我们看到的都是“它能干什么”:能写材料,能写代码,能画图,能聊天。
今天我想换一个视角:
我们不只是把 AI 当成一个工具来看,而是把它当成一个“会自己学习、会自己试错的智能体”来看。
这背后,支撑它“自己学会做事”的核心思想,就是——强化学习。
今天我们分五个部分:
- 先看一个走迷宫的小演示;
- 再用这个例子解释:什么是强化学习;
- 然后讲一讲:我们是怎么训练一个“智能体”的;
- 接着看看:强化学习在今天的大语言模型里扮演什么角色;
- 最后,回到“智能体(Agent)”这个概念:看看我们今天的 LLM-Agent 有什么局限,未来可能走向哪里。
好,我们先不讲概念,先看一个小实验。
1. 先看一个演示(约 5 分钟)
现在请大家看大屏幕,我打开一个网页,是一个走迷宫的机器人。
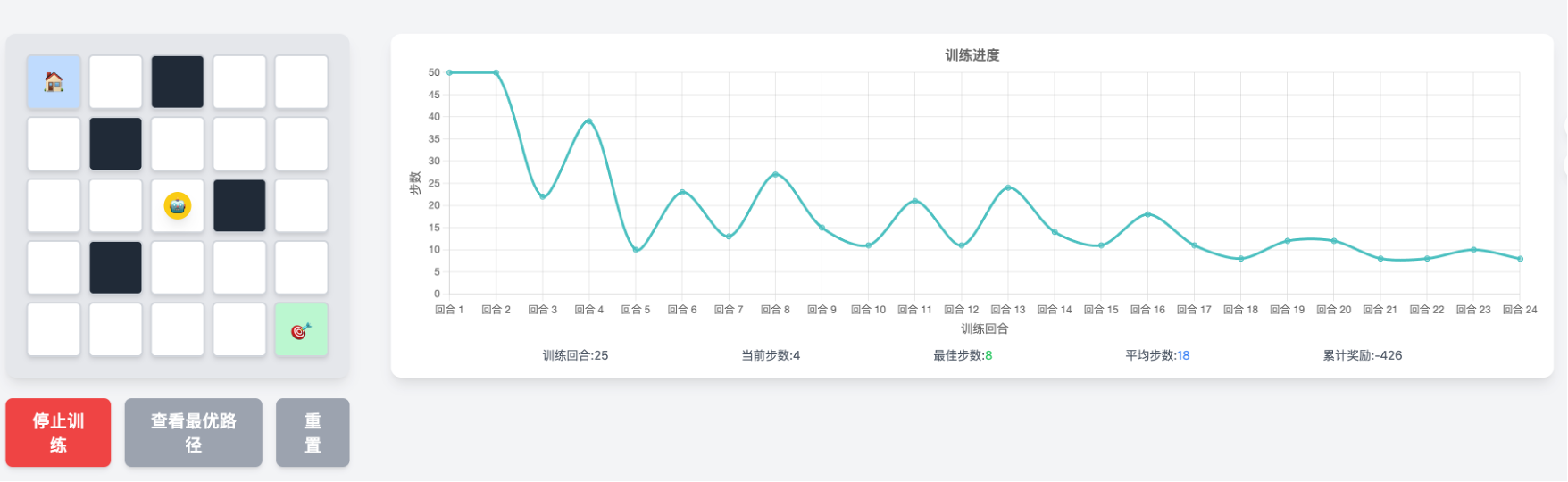
你会看到一个简单的迷宫,里面有一个小方块,就是我们的“机器人”。它的目标,是从起点走到终点。
我先让它“从零开始学”,一开始它什么都不会,只会瞎走:
——有时候撞墙,有时候绕圈,有时候往回走,看起来非常笨。一旦超时(五十步没走到终点),直接强制重启。
但是,我们在后台给了它一个非常简单的规则:
- 走到出口,给它一个正奖励+10;
- 负奖励:撞墙-5、多走一步-1;
- 其它情况,没有奖励。
然后我们让它不断地在这个迷宫里“试错”:
- 每走一步,它就记住:在这个位置,我刚才做了哪个动作,结果是好是坏;
- 下一次再遇到类似的情况,它就更倾向于做“历史上带来好结果的动作”。
我们把这个过程看完后,你会看到:
- 一开始完全乱走;
- 过一段时间,迷迷糊糊找到一条路;
- 再过一段时间,它开始走得越来越稳;
- 最后,它几乎每次都能以最短路径走出迷宫。
这个演示想说明什么呢?
第一,我们没有告诉它“正确路径”是什么。
第二,它完全是靠“自己试错 + 自己总结”,一步步学会的。
它学的是:
在什么状态下,该采取哪一个动作,才能在长期获得更高的奖励。
这就叫做强化学习。
2. 这就是强化学习(约 10–12 分钟)
刚才这个走迷宫的例子,就是一个最经典的强化学习场景。
我们先给它一个直观定义:
强化学习,是让一个“智能体”在环境中反复试错、根据奖励(好或坏的结果)来调整策略,从而学会在长期获得最高“回报”的一种学习方式。
2.1 和其他几种机器学习的区别
先把它和大家可能听过的另外几种学习方式对一对:
监督学习:
- 有一大堆“题目 + 标准答案”,模型的任务就是“尽量把答案预测正确”。
- 比如:给你一堆带标签的图片,“这是猫”“这是狗”,你学会区分猫狗。
- 像一个善于考试的做题家。
无监督学习:
- 没有标准答案,只有一堆数据,让模型自己去发现“模式”“结构”。
- 比如:给你一堆用户行为数据,让你自动分群,看看有哪些类型的用户。
- 像外部咨询专家。
强化学习不一样:
- 它没有直接的标准答案,只有“结果好不好”的信号;
- 它关心的不是“一次预测对不对”,而是“一串行动下来,整体好不好”。
- 业务骨干,真正解决实际问题的人。
2.2 强化学习的几个关键元素
听起来强化学习最靠谱,为什么呢?我来看看正式看一下,强化学习包含哪些元素。
以刚才走迷宫的 demo 为例,其实已经包含了强化学习的几个标准元素,我们用一点点术语来整理一下。
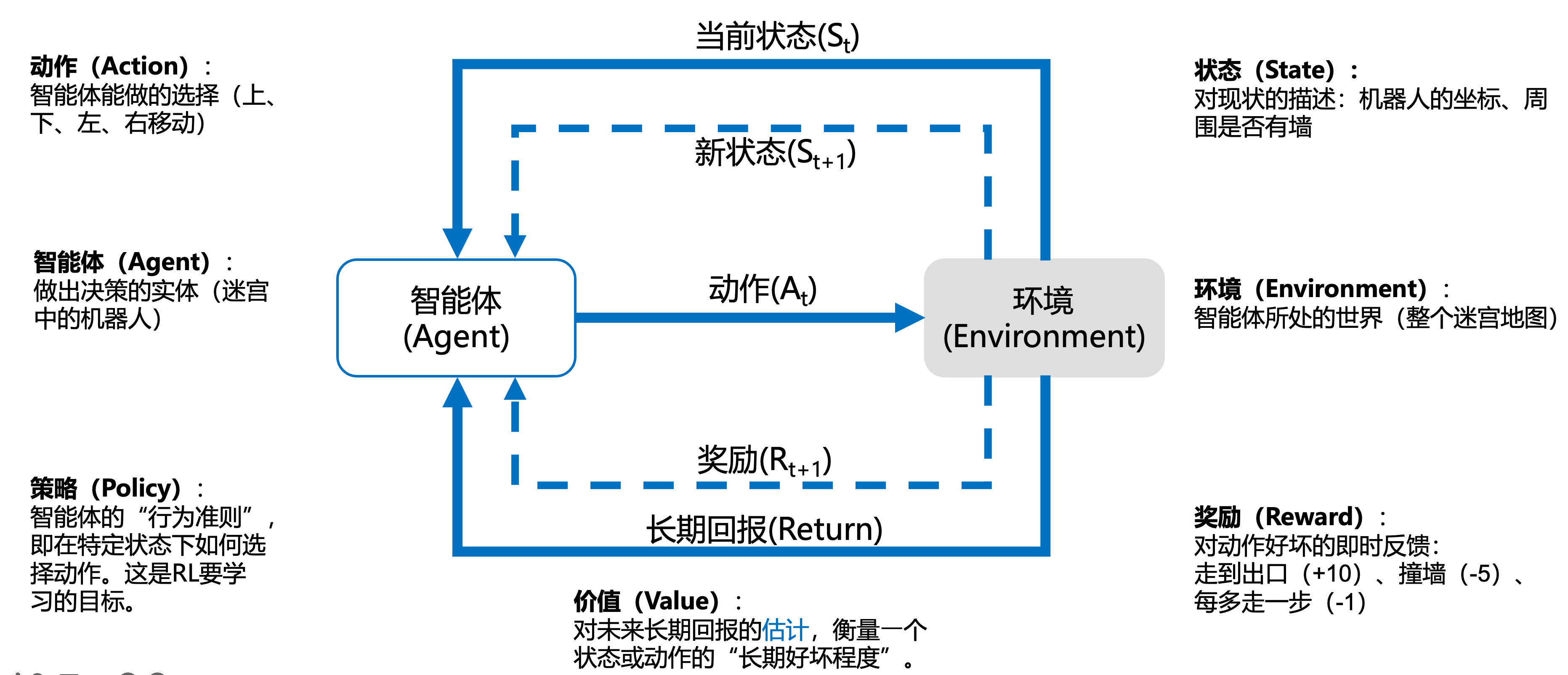
在强化学习里,一般有这些基本构件:
- 智能体 Agent:
那个在环境中“做选择”的东西,就是刚才的小方块机器人。 - 环境 Environment:
智能体所处的世界,刚才就是迷宫。 - 状态 State:
当前环境对智能体来说“长什么样”。
比如:机器人所在的坐标、附近墙的位置。 - 动作 Action:
智能体可以做的选择,比如:向上、向下、向左、向右。 - 奖励 Reward:
环境给智能体的一个分数:好行为给正分,坏行为给负分。
比如:到终点 +10,每多走一步 -1,撞墙 -5。 - 策略 Policy:
一套规则,告诉智能体“在某个状态下,怎么选动作”。
这就是智能体要学出来的“本事”。策略是智能体的“本我”。 - 回报 Return:
不只是看当前这一步的奖励,而是从现在到未来所有奖励的加权和。 - 价值 Value:
一个状态(或者状态+动作)的“长期好坏程度”,是对未来回报的一个估计。Return 是实际回报,Value 是估计。
如果简单概括一句话:
强化学习就是:
在状态和动作之间,学出一套“策略”,让长期累积回报最大。
2.3 再回到迷宫的例子,帮大家标一下元素
我们再回头看刚才的演示,用刚刚这几个概念重新看一遍:
- 智能体:迷宫里的那个小机器人;
- 环境:整个迷宫地图;
- 状态:机器人当前在第几格、上下左右是否是墙;
- 动作:四个方向的移动;
- 奖励:
- 到了终点,给一个大大的正奖励;
- 撞墙、走回头路,给小小的负奖励;
- 策略:
- 一开始完全是随机的;
- 后来经过多次试错,它形成了“在不同格子要怎么走”的经验。
所以要点是:
我们没有教它“迷宫的解法”,只是定义了奖励;
剩下的,都是它自己通过和环境互动学出来的。
2.4 “智能体”这个概念很关键
接下来,我们会不断用到“智能体(Agent)”这个词。我们稍微给它一个更有画面感的解释:
智能体,就是一个“能自己感知环境、自己做决定、自己采取行动,并且根据结果不断调整自己行为”的实体。 事实上智能体的英文 Agent一词源于拉丁语agens,即agere(意为“做、行动或驱动”)的现在分词,指具有行动能力的实体,通常拥有某种程度的自主性或委托权限,可被视为变革或事件的发起者。
它可以是:
- 看得见的:
- 机器人/狗、无人机、自动驾驶汽车;
- 春晚舞台上走路跳舞的机器人。
- 也可以是看不见的:
- 在电脑里玩游戏的 AlphaGo;
- 在服务器里根据交易数据自动调仓的量化交易机器人;
- 甚至你可以把“大语言模型 + 一套工具调用逻辑”,看作一个“看不见的智能体”。
强化学习研究的,就是如何系统性地训练这样的智能体。
3. 强化学习算法:训练智能体的方法(约 15–18 分钟)
有了直观概念,我们来讲一讲:
我们怎么从最简单的问题,一步一步走到复杂的智能体。
3.1 从最简单的“老虎机问题”说起:多臂赌博机(Multi-Armed Bandit)
先从一个非常简单、但非常经典的问题开始——“多臂赌博机”。
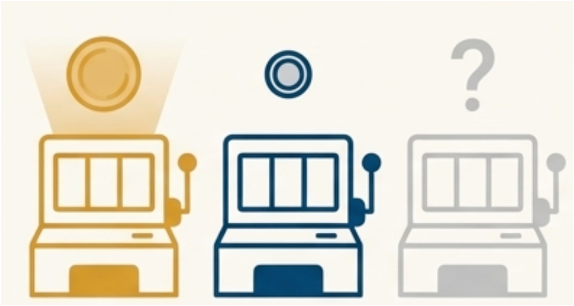
想象你走进一个赌场,有一排老虎机,每一台机子的中奖概率不一样,但你不知道哪一台更好。
每玩一次,就要投一次币,你的问题是:
在有限次数的情况下,怎么一边尝试、一边逐渐把精力放在更赚钱的机器上,让总体收益最大?
这就是多臂赌博机问题,它体现了强化学习一个很基础的矛盾:
- 探索(exploration):去试一试还不太了解的机器,说不定更好;
- 利用(exploitation):用你目前看来最好的那台,多赚一点。
解决这个问题,有各种算法:
比如 ε-greedy、UCB、汤普森采样等等,它们做的事情本质上是:
一边积累统计信息,一边控制好“探索 vs 利用”的比例。
这还是一个没有“状态”变化的简化版强化学习。
3.2 加上“状态”和“序列”:从走迷宫到玩游戏
再往前一步,就是我们刚才看到的走迷宫,以及更复杂的游戏 AI。
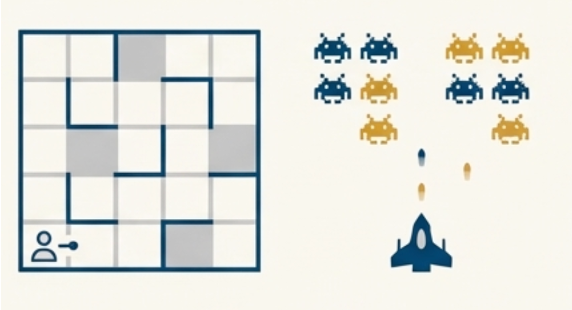
这里难度就大很多了:
- 每一步做什么,会影响后面能不能走得到终点;
- 有些决定一开始看起来有损失,但长期能走通;
- 最优策略看的是一整个序列的效果,而不是单步。
这时候就需要真正意义上的强化学习算法了。
大致有几类思路:
- 基于价值的(Value-based)
- 比如 Q-learning:
对每个“状态-动作”组合估一个价值(Q 值),
然后选择 Q 值最高的动作。 - 它核心在于:用“价值函数”来指导决策。
- 比如 Q-learning:
- 基于策略的(Policy-based)
- 直接学习一个“从状态到动作的概率分布”,
- 用梯度上升的方式让高回报的行为更可能被选中。
- Actor-Critic(“行动者–评判者”)方法
- 把两者结合起来:
- Actor 负责给出动作(策略);
- Critic 负责点评这一步好不好(价值或优势)。
- 把两者结合起来:
3.3 加上“高维感知”和“连续动作”:训练行走的机器人
如果再进一步,让智能体控制的是一个实体机器人,或者一个虚拟机器人,它要学会走路、转弯、平衡——问题就更复杂了。
这里的难点在于:
- 状态是高维的:关节角度、速度、加速度、传感器数据……
- 动作也是连续的:施加多大力度、关节转多少度,而不是简单的“上、下、左、右”。
这时候,就用到了深度强化学习(Deep RL):
- 用神经网络来近似策略和价值函数;
- 让智能体在模拟环境里不断尝试:
- 摔倒、站起、再尝试;
- 最终学会非常“自然”的走路和跳跃。
大家在网上可能看过 Boston Dynamics 的一些机器人视频,那背后就大量用到了类似的思想。
3.4 现实世界中的强化学习应用场景
强化学习已经在不少实打实的场景中落地:
- 游戏 AI:
- AlphaGo、AlphaZero:在围棋上达到甚至超过人类顶尖水平;
- Dota2 AI:通过自我博弈学会复杂团队配合。
- 机器人控制:
- 学会走路、抓取、堆叠物体、自动调整姿态。
- 个性化推荐:
- 根据用户的长期行为,优化“让你既不马上流失,又不会马上刷到烦”的内容组合。
- 金融交易:
- 根据市场反馈动态调整策略,控制风险。
- 自动驾驶:
- 在仿真环境里练习各种复杂路况,然后再小心地迁移到真实道路。
- 能源系统:
- 智能调度机组,平衡用电峰谷,降低总能耗。
3.5 强化学习的困难和挑战
说完好处,也要诚实地说一说它的难点:
- 样本效率低
- 需要尝试很多次才能学出一个好策略;
- 在仿真环境里可以跑几百万局,但现实世界不能让机器人真的摔一百万次。
- 奖励设计很难
- 你奖励什么,智能体就会靠近什么;
- 奖励设计不好,很容易学出“歪门邪道”:
比如游戏里为了拿分,干一些违背人类直觉的奇怪操作。
- 训练不稳定
- 特别是深度强化学习,超参数敏感、容易发散。
- 可解释性差
- 最后学出一个复杂神经网络策略,很难解释“为什么在这里做这个决定”。
- 探索有风险
- 在虚拟环境里乱试,最多游戏崩掉,没啥影响;
- 在现实世界里乱试,有安全风险——比如无人车不可能靠“乱开”来学。
所以你可以把强化学习理解为:
它代表了一条非常有潜力,但也很“难驯服”的 AI 技术路线。
4. 强化学习助力大语言模型(约 12–15 分钟)
聊完“传统”强化学习,我们回到大家最近最关心的大语言模型。
像 GPT、Claude、DeepSeek、Kimi 等,我们今天看到的这些“会聊天的 AI”,它们背后也用到了强化学习,尤其是两种典型做法:
- 用人类偏好做奖励信号:RLHF;
- 用客观可验证的标准做奖励:比如 DeepSeek R1 这类“自我验证”的方式。
4.1 RLHF:用人类偏好当奖励信号
RLHF,全称是** *Reinforcement Learning from Human Feedback,翻译过来就是:*“从人类反馈中做强化学习”**。
它解决的是一个很现实的问题:
大模型预训练完,会说话,但不一定好好说话。
有时候答非所问、有时一本正经胡说八道,有时给出不安全的内容。
怎么办?直接写规则是不可能的——太复杂了。
于是,大家想到用强化学习的方式来“矫正”。
大致流程是这样的:
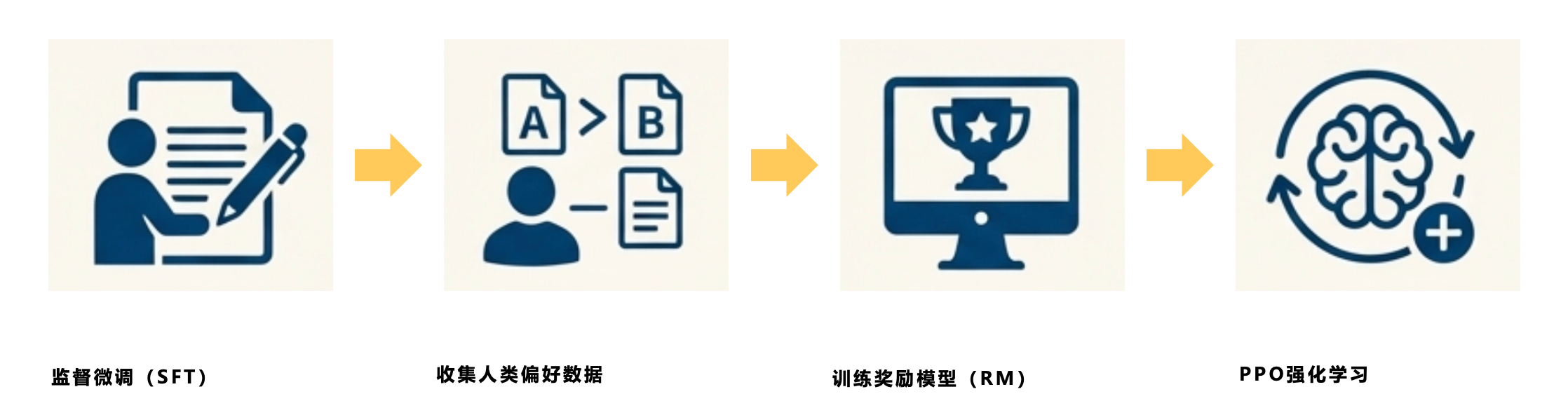
- 先有一个预训练好的大模型
- 它已经学会了“如何接着写下一句”,
- 但它只是语言上的强,价值观、礼貌、不胡说这些都没有保证。
- 人工写一些“理想回答”示例(监督微调 SFT)
- 比如:给它一个提问,让标注员写出“我们希望模型怎么回答”;
- 用这些高质量示例再训练一次模型,让它学会基本的“听话”。
- 模型自己生成多个回答,人来打分
- 现在,给同一个问题,让模型生成两三个不同版本的回答;
- 请标注员打个“好坏排序”,比如 A 比 B 好。
- 训练一个“奖励模型”
- 把这些“排序”喂给一个小模型,让它学会:
- 给定问题和回答,它能打出一个“人类喜不喜欢”的分数。
- 这个小模型就扮演了Reward(奖励函数) 的角色。
- 把这些“排序”喂给一个小模型,让它学会:
- 用强化学习(一般是 PPO,属于Actor-Critic 类算法)来调整大模型
- 现在,我们让大模型出答案;
- 奖励来自刚刚那个“奖励模型”;
- 用强化学习的方式,让大模型更倾向于生成高分回答。
这种做法,本质上就是:
用人类偏好作为 Reward,
把一个“会说话的模型”微调成一个“更符合人类期望的助手”。
所以,我们平时使用的大语言模型,已经不是单纯的“语言预测器”,
而是经过了一个“软性强化学习训练”的对话智能体。
4.2 DeepSeek R1:用“客观可检验结果”做奖励
另一种做法,是像 DeepSeek R1 这样的模型,强调的是:
尽量使用“客观的、可自动验证”的信号来做奖励。
比如:
- 做数学题:答案对不对,一算就知道;
- 写代码:跑一跑测试用例,能不能通过;
- 证明问题:有没有逻辑漏洞、能不能被自动验证器验证。
在这种场景下,Reward 就从“人类主观打分”变成了“通过 / 没通过”这样的客观信号。
好处是:
- 不需要大量人工打分,节省成本;
- 奖励更“硬”:对就是对,错就是错,不那么依赖人情世故;
- 模型会倾向于发展出更“严谨”的推理过程。
你可以把这两条路线理解为:
- RLHF:学会“说人话,说得让人舒服”;
- 类似 DeepSeek R1 的做法:学会“做对事,自证正确”。
未来这两条路线大概率会结合起来:
既要“说得好听”,又要“做得正确”。
4.3 一些不同观点:李飞飞、LeCun、Sutton
在大语言模型爆火之后,学界有很多讨论,我简单提几位代表人物的观点:
- 李飞飞:
一直强调“感知 + 具身智能(Embodied AI)”——
认为光看语言还不够,AI 需要和视觉、动作、物理世界结合起来,这跟强化学习、世界模型的方向是接近的。 - Yann LeCun:
对现有大模型有点“毒舌”:- 他认为现在的大语言模型,虽然很有用,但远不是通用智能;
- 它缺乏真正的“世界模型”和“长期规划能力”;
- 他主张构建一种“可以自主预测世界、在世界中试验的智能体”。
- Rich Sutton:
强化学习之父,他有两篇文章流传甚广,一篇是 2019 年的《The Bitter Lesson》和 2025 年的《Welcome to the Era of Experience》。- 在《The Bitter Lesson》里,他说:
历史告诉我们,靠人类设计结构不如靠“算力 + 通用算法(搜索 + 学习)”; - 在《Welcome to the Era of Experience》(我之前翻译了中文版,可阅读全文)里,他又提出:
人类数据时代会过去,接下来是“经验时代”,也就是智能体通过和环境互动来不断获取新经验。
- 在《The Bitter Lesson》里,他说:
这里有一个很有意思的点:
语言本身,是人类设计出来的一种“压缩世界”的方式。一旦人类产生的数据用光了,智能就到顶了。
我们今天的大语言模型,是在大量人类语言数据上训练出来的,
这让它很擅长模仿人类说话、总结人类已有知识。
但从 Sutton 的眼光来看,这也意味着:
- 它的“天花板”在一定程度上被“人类语言”这层壳限制住了;
- 要突破人类语言的边界,可能需要更直接地和环境交互,用自己的“经验数据”来学习,而不仅是“重复人类说过的话”。
4.4 顺带说一句:什么是“世界模型”?
刚才提到“世界模型”,简单说一句:
世界模型,就是智能体脑子里关于“这个世界是怎么运转的”的一个内部模拟。
比如:
- 你知道“杯子被推到桌子边会掉下去”,这就是一个世界模型;
- 智能体如果有世界模型,它就可以在脑子里先想一想:“如果我这么做,会发生什么?”
而不是盲目去“尝试–摔跤–再尝试”。
这和强化学习结合起来,就变成了:
- 用经验数据学出世界模型;
- 在世界模型里做规划、推理、搜索;
- 再把好的策略拿到真实环境中去执行。
这,也是很多人认为“真正强大的智能体”要走的一条路。
5. 智能体的现状和未来(约 12–15 分钟)
最后一部分,我们回到今天经常听到的一个词:Agent(智能体)。
5.1 先回顾一下“智能体(Agent)”的概念
我们一开始说过:
智能体,就是一个能感知环境、能自主决策、能采取行动、并根据反馈不断调整行为的实体。
在强化学习里,这个定义很自然。
那在今天的大语言模型时代,“Agent”这个词被用得更广了。
现在很多产品都在讲 “LLM-Agent”,比如:
- 写代码的 Claude Code、GitHub Copilot、Cursor 等;
- 助理型产品:Kimi、豆包、ChatGPT 多工具版;
- 以及各种“套壳 Agent”,比如 Manus、Genspark 等,用一套流程去驱动多个工具和模型。
5.2 用一个框架图看 LLM-Agent
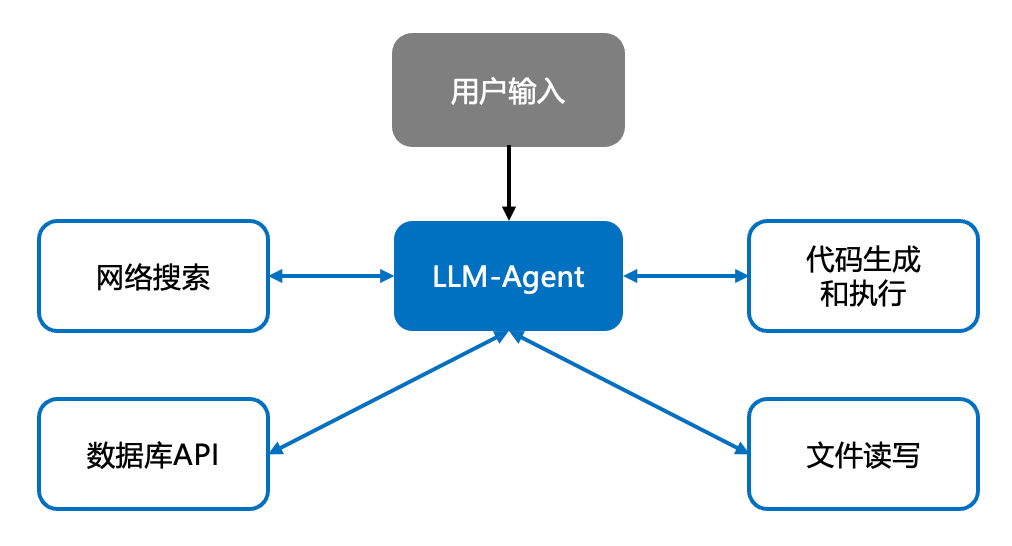
大致结构是这样的:
- 用户给一个任务:
- 比如“帮我分析这份报告,顺便写一个总结”;
- 或者“帮我写一段代码,并在服务器上跑一下”。
- Agent(本质是一个大语言模型):
- 先把这个目标分解成一系列子任务;
- 再根据需要调用各种工具(搜索、浏览器、数据库、代码运行环境等)。
- 工具 / 环境:
- 比如网络搜索、企业内部系统、终端、浏览器、API 接口……
- 把结果返回给 Agent。
- Agent 综合这些结果,再做下一步决策,
- 最后给用户一个看起来很完整的“解决方案”。
从用户角度看,它确实有点像一个“能干活的智能助手”:
- 会看文件、会查资料、会写代码、会跑程序;
- 每一步都能用自然语言解释给你听。
5.3 先肯定一下:今天的 LLM-Agent 已经很强
先肯定一点:
作为“即用型工具”,今天的 LLM-Agent 已经非常有价值。
- 它可以极大地提高我们个人效率;
- 在很多工作流程中,它可以帮我们自动化“80% 的重复性工作”。
从工程角度、产品角度,它的意义是巨大的。
5.4 但它还有哪些根本性的局限?
如果我们用“强化学习”和“真正的智能体”的视角,再苛刻地看一眼今天的 LLM-Agent,会发现它有一些结构性的局限。
(1)是离线学出来的 policy,而不是在线学习,因此无法持续学习
- 今天的大模型,本质上是一个**“训练好以后参数固定”的策略(policy)**;
- 上线之后,它在和你的对话中,几乎不会根据“成功与失败”去更新自己的参数。
也就是说:
它在和你对话的时候,其实没有在真正“学”,
它只是把训练阶段学到的模式,尽量发挥出来。
这和强化学习中的智能体有一个本质差异:
- 强化学习智能体,在环境里试错、积累经验;
- 经验会反向更新策略 ,策略变得越来越好。
现在的 LLM-Agent,绝大多数是一次性训练,长时间使用,不具备这样的在线改进能力。
(2)状态感知短视,长期记忆和环境建模薄弱
- 它“看到的世界”,基本上就是以文字形式输入的上下文(Prompt 为主);
- 再长一点,就靠一些“记忆插件”或“搜索历史”,但这都是外部的拼接。
从强化学习的角度看,它几乎没有能力:
建立一个“世界状态在长期怎么变化”的内部模型,
更谈不上 POMDP 里那种精细的 belief 更新。
所以你会发现:
- 在短对话、一次性任务里,它表现很好;
- 一旦涉及长期项目、跨周跨月的任务,它就变得力不从心。
(3)运行时没有明确 Reward,目标主要靠人类外包与隐含偏好
在我们刚才讲的强化学习框架里,有一个特别重要的东西叫 Reward。
- 智能体清楚知道:什么行为会带来高奖励;
- 它会自动地朝着这个方向去优化长期策略。
而今天的 LLM-Agent:
- 在运行时,基本没有显式的 Reward;
- 它不知道“你这一次满意不满意”在系统内部是怎么被衡量的。
它“优化”的,是在训练阶段形成的一些隐含偏好:
- 比如“说话要礼貌”“不能输出违规内容”“尽量详细一点”;
- 但这些并不是在你这一次任务上实时计算出来的 Reward。
结果就是:
它很容易在“表面指标”(proxy)上表现很好,
但在你真正关心的目标上容易翻车。
比如:
- 回答看起来非常自信、非常流畅,但事实错误;
- 代码能跑,但在边界条件上有 bug。
(4)探索主要停留在“语言内心戏”,真实环境中的 RL 式试错极少
你可能看到过一些“思维链”(Chain-of-Thought)的例子:
- 模型会在回答前,自言自语地想好几步;
- 这是一种“语言空间里的探索”:它在脑子里尝试不同的解题思路。
但和强化学习里的“真实探索”不一样:
- 在 RL 里,智能体真的去做动作,看到真实后果,再更新策略;
- 在 LLM-Agent 里,它很少有机会在真实世界里试错。
原因也很现实:
- 一旦让它真的去发邮件、下单、调交易 API、控制机器人,风险太大;
- 所以我们必须加一堆安全限制、人工审核,这就大大压缩了它“自由探索”的空间。
从强化学习的视角来看:
今天的 LLM-Agent 是“脑补能力很强”,
但缺乏“在真实环境中滚打一圈再改进策略”的能力。
(5)动作空间高度非结构化,闭环安全难以保证
在强化学习的很多场景里,动作是结构化的:
- 要么是有限的几种动作(上、下、左、右);
- 要么是连续的控制量(油门多少、转向多少)。
这样有什么好处?
——好约束,好验证。
而 LLM-Agent 的主要动作是什么呢?
是自然语言 + 工具调用。
自然语言非常灵活,非常强大,但从安全和控制角度看,它也是:
- 高维度;
- 语义不确定;
- 很难完全穷尽所有可能。
比如:
- 你很难事先写出一套规则,保证“它的话语绝对不会导致某个工具被危险地使用”。
从闭环控制和安全的角度,这是一件非常麻烦的事。
所以,我们现在更多依赖的是:
- 黑名单;
- 后置安全过滤;
- 人类监管。
这和我们在强化学习里能做到的“精确定义动作空间、严格验证策略”差距很大。
(6)缺少长期价值与分层策略的显式建模
最后一点,也是最关键的:
- 真正的强化学习智能体,会发展出某种“长期价值函数”和“分层策略”;
- 它会知道:“先吃点亏,后面会有更大收益”;
- 它会发展出不同时间尺度上的“子技能”。
而今天的 LLM-Agent,本质上更像是:
一个非常强大的即时决策器:
在当前这一次对话、这一轮任务上,它能给出很聪明的解法;
但在“怎么为未来十步、百步做打算”这个维度上,它几乎没有显式建模。
这也就是为什么,从强化学习的角度看,我们会说:
今天的 LLM-Agent,
更像是一个“长在语言上的超级函数”,
而不是一个“可以长期在环境中试错、不断提升回报的智能体”。
5.5 未来的 Agent 可能是什么样子?
最后,简单谈一谈“未来可能出现的 Agent 形态”。
如果我们把前面提到的 Sutton 的那句话放在心里:
“应该偏爱那些可以随着算力增长无限扩展的通用方法——目前看就是两类:搜索(search)和学习(learning)。”
再结合他在《Welcome to the Era of Experience》里说的:
“人类数据的时代之后,会是体验的时代。”
我们可以大胆一点推测:
未来真正强大的智能体,很可能具备这些特征:
有长期、流式的经验不再是“一次性对话”,而是和你一起工作、生活很长时间。
- 它记得你过去的选择,知道你真正看重什么。
有丰富的“身体”和“感官”,不一定是物理机器人,最起码要深度接入数字世界。
- 文件系统、业务系统、网络环境、传感器、甚至 IoT 设备。
有清晰、可调整的奖励信号,不只是“人类打个分”,而是结合多种信号且及时调整。
- 综合业务指标(效率、安全、成本)、用户满意度、环境中的各种可测量信号。
- 能在觉察到智能体“钻空子”之后迭代奖励信号,从而避免回形针效应。
有自己的世界模型和规划能力
- 能预测“如果我这么做,世界会怎样变化”。
- 能在脑子里做各种模拟。
- 再决定真正要采取什么行动。
会持续在线学习
- 每一次成功和失败,都会反哺到策略中去;
- 它不会永远停留在“出厂时的水平”,而是在你身边越用越聪明。
这样一种智能体,就更接近我们在强化学习里追求的那种:
“和人类对齐目标,然后靠自己去探索世界、积累体验,
在长期回报意义上越来越聪明”的 Agent。
这,也许才是 Sutton 所说的“体验时代”的含义。
结尾(约 2–3 分钟)
最后,我用一句话总结今天的分享:
- 强化学习,是一套让智能体通过试错,在环境中学会“长期做对事”的方法;
- 大语言模型,已经开始用强化学习(特别是 RLHF、以及像 DeepSeek R1 那样的客观奖励)来对齐人类偏好;
- 今天的 LLM-Agent,作为工具已经非常有用,但从强化学习的视角看,离“真正会在世界中积累经验的智能体”还有一段距离;
- 未来的智能体,大概率会走向:
- 嵌入到趋向无限的体验流中、
- 更丰富的行动空间、
- 更清晰灵活的奖励、
- 更强的世界模型与规划能力。
我们现在站在一个很有趣的时间点上:
过去十年是“人类数据驱动的大模型时代”,
接下来的十年,很可能是“体验驱动的智能体时代”。
谢谢大家。



